RoBERTa
RoBERTa
Introduction
본 저자들은 BERT가 undertrained 되어있다고 생각한다. 따라서 이를 해결하면 초기의 BERT의 성능을 뛰어 넘을 수 있을 것이라고 판단한다. 이를 위하여 BERT의 hyperparameter를 조정, BERT의 Next Sentence Prediction을 제거, 학습 데이터를 늘리는 등의 노력을 하여 BERT 보다 더 좋은 성능을 가지는 RoBERTa를 내놓았다.
- 모델에 학습 데이터를 길고, 큰 batch size, 많은 데이터로 하여 모델을 학습
- 여기서 사용한 데이터가 CC-NEWS라는 데이터셋 인데, 이 데이터셋이 학습 사이즈를 늘리는 등의 역활을 잘 해줬다고 한다.
- next sentence prediction을 제거
- 학습 데이터를 긴 sequence로 진행
- masking pattern을 dynamically하게 변경하여 적용하여 학습
요약하자면, 1. BERT를 tuning하는데 중요하게 사용되는 hyperparameter나 strategy를 소개한다. 2. 새로운 데이터인 CC-NEWS를 사용하여 다른 task에서 성능향상을 이끌었다. 3. masked language model이 제대로만 학습된다면 엄청나게 경쟁력있는 모델임을 보여준다.
Background
Bert에 관한 전반적인 이야기를 풀어낸다.
Setup
BERT의 입력은 2개의 segment가 들어가게 되는데, 이 segment들의 분리를 위하여 special token을 넣어준다. 문장 1(x1,…xn)과 2(y1, … , yn) 가 있을 때, [CLS], x1, ... ,xn, [SEP], y1, ..., yn, [EOS]로 입력이 들어간다.
Masked Language Model
입력 sequence값에서 15%가 [MASK]로 마스킹 된다. 그리고 이 마스킹된 부분을 예측하는 것으로 학습이 진행되는데, cross-entropy loss를 사용하여 loss를 줄여가며 학습하도록 한다.
마스킹 하는 부분에서 추가적인 작업이 들어가게 되는데,
- 80%는 토큰을 [MASK]로 바꿔준다.
my dog is cute -> my dog is [MASK] - 10%는 토큰을 바꾸지 않는다. 이는 실제 관측된 단어에 대한 표상을 bias해주기 위해 실시합니다.
- 10%는 토큰을 vocab에서 랜덤으로 선택하여 넣는다.
my dog is cute -> my dog is banana
BERT에서는 masking을 학습을 시작할 때 한번밖에 안해주기 때문에, 데이터가 복제된다고 한다. 따라서 매 학습할 때마다 mask가 같지않다고 한다. 이는 4.1에서 설명하니까 읽고 다시 정리
Next Sentence Prediction
NSP는 binary classification loss로 두개의 문장에서 어느 문장이 뒤에 와야하는지 예측하는 것이다.
positive example : text corpus에서 연이은 문장을 선택하는 경우
negative example : text corpus에서 연이어 지지 않는 문장을 선택하는 경우. 즉, 다른 document랑 연결되는 문장을 선택하는 것을 의미한다.
NSP는 Natural Language Inference task에서 성능을 향상 시키기 위해서 적용된 것이다. 이 task는 문장들 간의 관계에 관한 추론을 하는 task이다.
Optimizer
BERT는 Adam optimizer를 사용했고, 파라미터는 $\beta_1$ = 0.9, $\beta_2$ = 0.999, $\epsilon$ = 1e-6, $L_2$ weight decay 0.01이다. learning rate warm up은 첫번째 10,000 step을 적용하고, 1e-4에 도달하면 선형적으로 감소한다. 모든 layer, attention weight는 0.1의 dropout을 가진다. 학습에 사용된 batch size는 256이고, max token length는 512이다.
Data
BookCorpus + English Wiki ⇒ 16GB
Experimental setup
대부분 기존 BERT의 hyperparameter를 따랐지만 달리진 점은 아래와 같다.
- learning rate의 peak를 넘겨서 잡았고, warmup steps를 다르게 했다. 각 세팅마다 다르게 설정함.
- adam optimizer의 $\beta_2$ = 0.98로 설정 / large batch size에 안정적이도록!
- Sequence length를 주로 512에 맞춰서 데이터를 구성하고, 짧은 데이터는 사용하지 않았다. 원래 BERT의 저자들은 pre-training 의 처음 90%는 짧은 길이(128,256) 로 학습하고 남은 10%에서 full length로 이용하도록 권장하지만, RoBERTa는 처음부터 512로 학습을 진행하였다.
DATA
BERT와 같은 style의 model은 학습 데이터가 많을 수록 더 좋은 성능을 낸다고 한다. 따라서, 기존 BERT보다 10배 많은 데이터를 사용하여 학습을 진행하였다.
- BOOKCORPUS
- CC-NEWS
- OPEN WEBTEXT
- STORIES
Evaluation
- GLEU
- SQuAD
- RACE
Training procedure analysis
used Bert base model
Static vs Dynamic Masking
기존 BERT에서는 마스킹을 학습을 시작할 때 한번밖에 진행하지 않는다. 이를 논문에서는 single static mask라고 표현한다. 이와 같이 마스킹이 매번 같은 문제를 해결하기 위해서, 학습 데이터를 10개로 복제하고, 각각 다르게 masking을 적용하는 방법을 사용한다. 그럼 총, 10개의 마스킹이 다른 학습 데이터를 4번 돌아서 40 epoch를 맞춰 학습한다. 이와 같은 방법을 dynamic masking 이라고 한다.
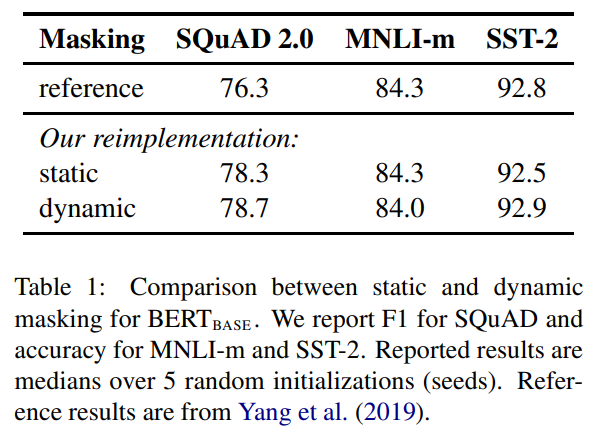
실험 결과는 위와 같다. static은 기존 BERT와 비슷한 성능을 보이고, dynamic은 기존 BERT보다 조금 낫거나 경쟁력있는 차이를 보인다.
Model input format and next sentence prediction
BERT에서는 NSP loss가 추론하는 task에 있어 학습에 사용되는 중요한 요소라고 소개하며, 이를 제거했을 경우 성능이 떨어지는 것을 예로 든다. 그러나 이는 단순이 NSP loss만 제거하고 두개의 segment가 입력으로 들어가는 구조는 유지했기 때문에 나타난 결과였다. BERT이후의 많은 연구들이 NSP loss가 정말 필요한지 의문을 가진다. 이를 다시 검증하기 위해서 아래와 같이 4가지의 입력 구성으로 하여 실험을 진행하였다.





- segment-pair + NSP : BERT와 동일한 설정 / 두개의 segment pair와 총 길이는 512 이하, NSP loss 사용
- sentence-pair + NSP : 각 segment가 문장으로 구성된다. 각 입력이 512 토큰 보다 매우 짧기 때문에, batch-size를 늘려서 기존 BERT에서와 같이 optimize되는 토큰의 개수를 비슷하게 설정하였다.
- full-sentence : 입력은 하나 이상의 문서들에서 연속적으로 샘플링됌. 입력의 길이는 거의 512와 유사하다. 만약에 입력의 하나 문서가 끝나면, 다음 문서로 그대로 연결해서 총 토큰 개수가 최대 길이를 최대한 채우도록 구성하였다. NSP 사용 X
- doc-sentences : 입력이 거의 문장 전체로 되어있고, 3번 설정과 비슷함. 만약 입력이 문서의 끝쪽에서 끝나게 되면 512보다 작게 된다. 이를 해결하기 위해서 dynamic하게 batch size를 늘려서 적용함. NSP 사용 X
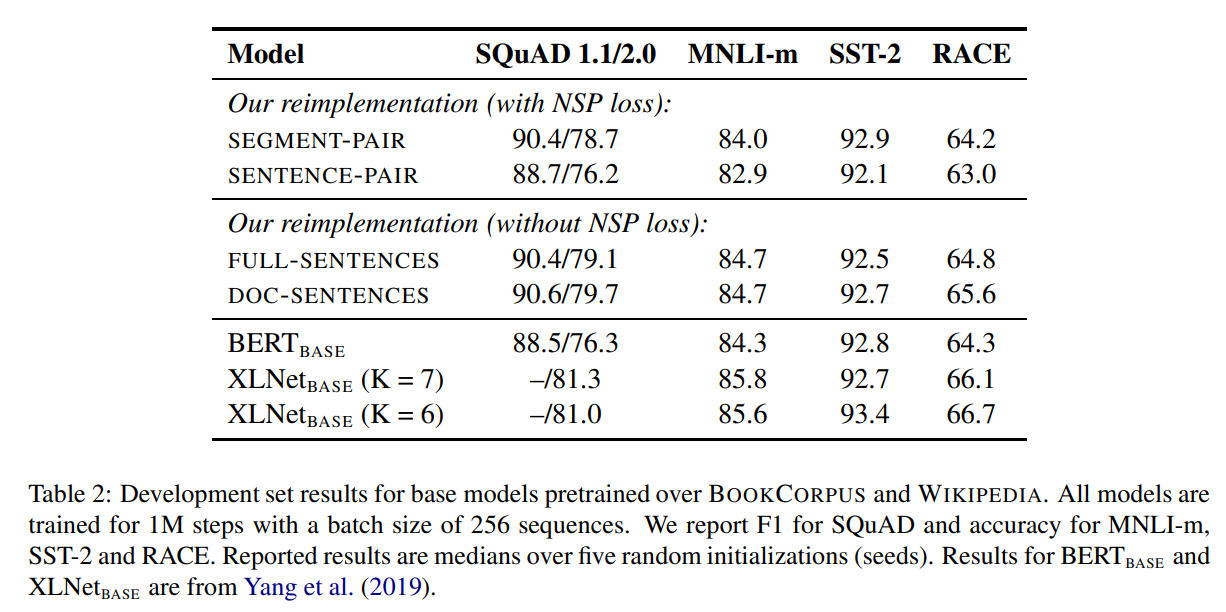
실험 결과, segment-pair / sentence-pair의 결과를 통해서 각각의 sentence를 사용하는건 성능에 악영향을 끼치는 것을 보여줬다. 이는 모델이 long range dependency를 학습할 수 없었기 때문이다.
full-sentence와 doc-sentence에서는 NSP loss를 사용하지 않았으며, 그 결과 성능향상을 확인할 수 있었다. 또한, 기존 BERT에서는 segment는 남기고 NSP loss만 지운것이 성능에 어떻게 영향 미치는지 확인되는 부분이다. 따라서 RoBERTa에서는 성능이 가장 좋은 doc-sentence를 쓰려했으나, 이는 batch-size가 너무 다양하게 바뀌어야 하기 때문에 full-sentence를 사용한다.
XLNet과 큰 성능 차이가 나는 이유는 위의 실험들은 더 적은 데이터(Bookcorpus + Wikipedia)로만 학습했기 때문입니다.
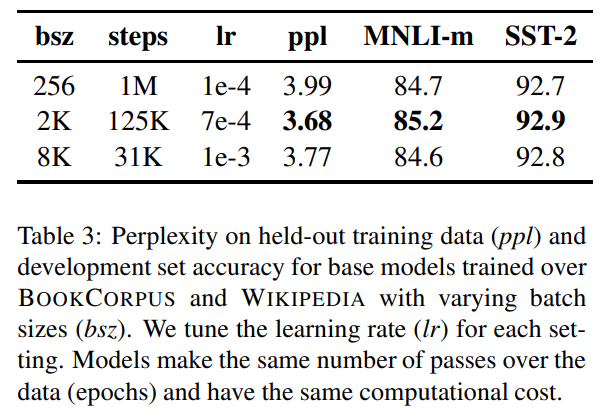
Training with large batches
최신 연구에서는 더 큰 batch size와 이에 따른 적절한 learning rate를 사용하면, optimization 속도 뿐만 아니라 성능도 향상되는 것을 보여준다.
기존 BERT에서는 1M step 을 batch size 256으로 학습했다. 저자들은 기존 BERT와 같은 계산비용을 유지하면서 125K step을 batch size 2K로 하거나, 31K step을 batch size 8K로 학습하였다. 실험 결과 큰 batch size로 학습한 경우 preplexity가 개선되는 것을 확인하였다.
text encoding
BPE는 char와 word level의 혼합된 형식을 가시는 subword tokenizer이다. 이는 큰 데이터를 기반으로 통계적으로 단어를 subword로 쪼갠다.
BERT에서는 학습 코퍼스에 휴리스틱한 tokenizing을 진행하고, char level BPE로 학습시켰다. vocab은 30K이다.
반면에 논문에서는 GPT의 byte level BPE를 학습했고, 50K vocab을 이용했다. 이 작업에서는 사전의 크기가 커졌기 때문에 BERT base에서는 15M, BERT large에서는 20M의 추가적인 파라미터가 이용되었다.
선행 연구에서는 BPE가 char보다 성능은 안좋지만, universal한 encoding을 위하여 BPE를 적용하기로 하였다.
RoBERTa
- Dynamic masking
- full sentence & remove NSP
- large batch size
- byte-level BPE
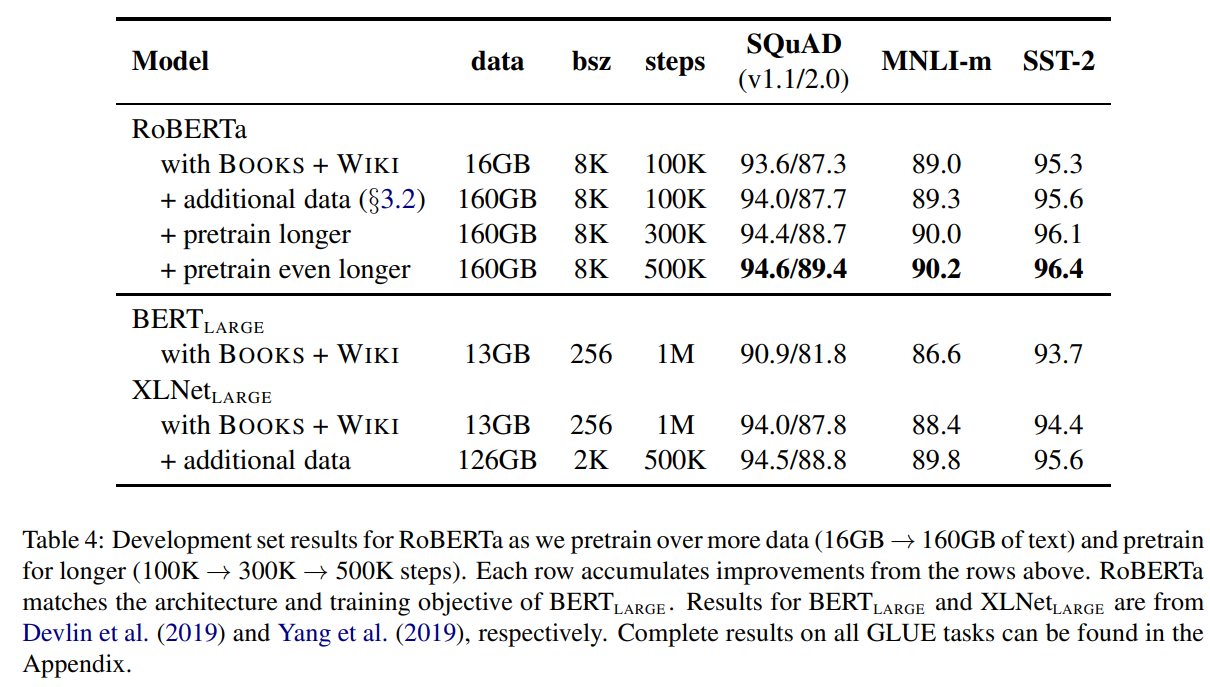
실험 결과 기존 BERT large보다 더 좋은 성능을 가지는 것을 확인함. 추가적인 데이터를 넣었을 때, 더 길게 학습했을 때, 더 더 길게 학습했을 때 성능도 추가적으로 넣었다. 결과를 보면, XLNet보다 더 좋은 성능을 가지는 것을 확인할 수 있었다. 학습을 500K 까지 늘려도 overfitting되는 경향은 보이지 않았다.
GLUE result
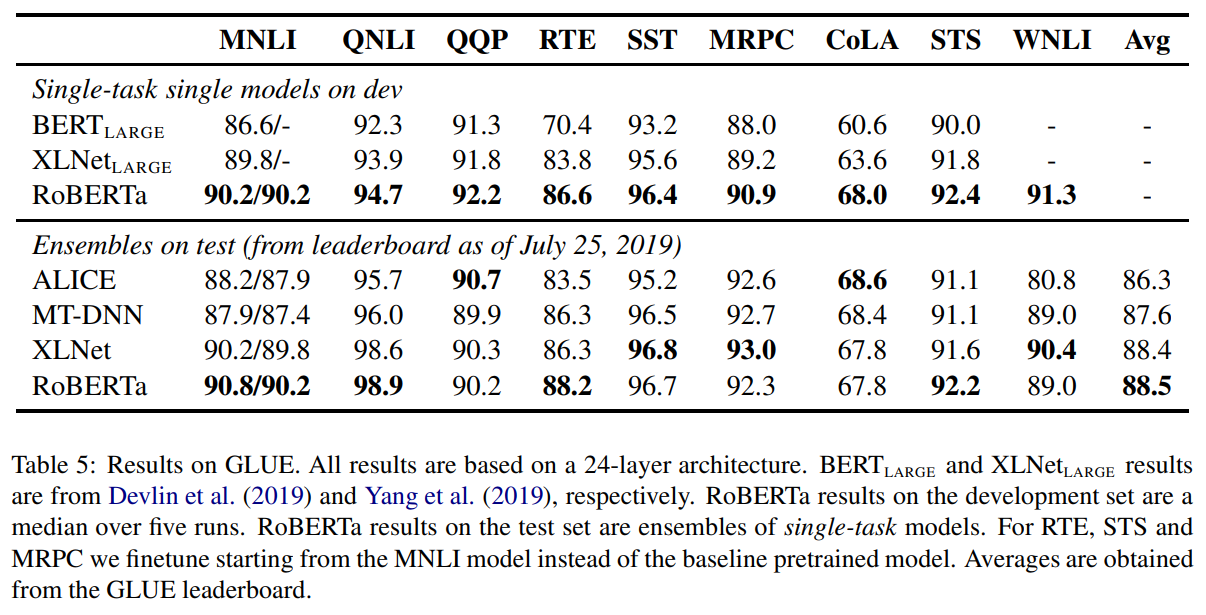
- single model : GLUE 의 모든 테스크들에 대해 각각 single-training을 진행했고, 다른 논문들과 유사하게 hyper-parameter는 적절하게 선정하여 학습함. 여기서 차이점은 BERT 및 다른 논문들은 3epoch 만 학습한 반면에, RoBERTa는 10 epoch와 early stopping을 적용하였다.
- ensemble model : RTS, STS and MRPC는 MNLI로 fine-tuning 된 모델을 다시 fine-turning하는 것이 성능이 좋았다. (MNLI가 pair단위 task중에서 데이터의 양이 가장 많기 때문인것 같다고 한다.) 조금 더 다양한 hyperparameter를 실험에 적용하였고, 5-7개 모델을 ensemble하였다.
실험 결과 single model에서는 제안한 모델이 가장 좋은성능을 보이고, 모든 task에서 우수한 성적을 거두었다. 중요한 점은 RoBERTa도 BERT large와 같은 MLM을 사용했는데 성능은 어느 모델보다 더 좋은 결과를 보였다. 논문에서는 이런 결과를 보고, 모델 구조나 pretraining objective를 향상시키는 것에 대해 의문점을 가지고, 일반적인 데이터 크기나 학습시간에 초점맞추는 것이 상대적으로 더 중요할 수 있다고 주장한다.
ensemble model에서는 9개의 task중에서 4개, 그리고 평균값에서 가장 좋은 점수를 얻었다. RoBERTa는 다른 모델들과 달리 multi-task fine-turning을 하지 않았다고 한다.
SQuAD result
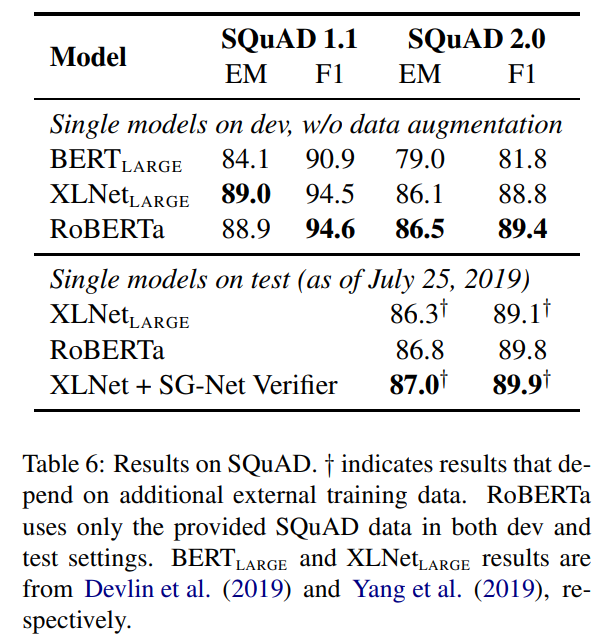
BERT와 XL-Net에서는 추가적인 QA dataset를 통해서 모델을 튜닝하여 성능을 냈지만, 본 논문에서는 오로지 제공된 데이터만으로 이루어낸 성능임을 강조한다. 그 결과 SQuAD 1.1 에서도 좋은 성능을 냈다. SQuAD 2.0 에서는 스팸 분류기를 결합하여 학습했는데 역시 성능이 좋았다.
RACE result
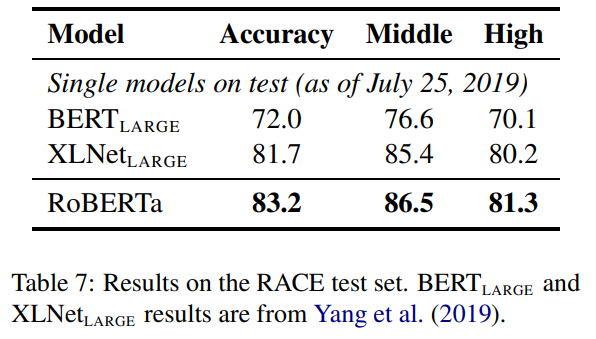
RACE는 단락을 주고 그에 해당하는 정답을 4개 중에서 1개를 찾아 맞추는 방식으로 이루어진다. 이를 위해서 약간의 튜닝을 진행했고, 그 결과 모두 좋은 점수를 얻었다.
Conclusion
Roberta는 BERT가 아직 과소적합되어있으며, 몇몇 학습파라미터, 학습방식을 변경함으로써 BERT가 좀 더 나은 성능을 낼 수 있음을 보여주었다. 이로써 이전의 연구에서 간과된 요소들의 중요성을 확인하고, 최근에 제안된 다른 모델과 겨루어도 충분히 경쟁력이 있을 수 있음을 보여주었다.
Reference
https://speakerdeck.com/himkt/roberta-paper-reading
Roberta paper