한글코드 (ks완성형, cp949, utf-8)
인코딩 & 디코딩
인코딩이란, 사용자가 입력한 문자나 기호들을 컴퓨터가 이용할 수 있는 신호로 만드는 것을 의미한다. 컴퓨터가 이해할 수 있는 신호로 변경하는 것이 인코딩이라면 컴퓨터가 보낸 신호를 사용자가 이해할 수 있게 변경하는 것은 디코딩이라고 한다.
인코딩과 디코딩을 하기 위해서는 정해진 테이블(table)을 기준으로 입력과 해독이 처리되어야 하는데, 이를 문자열 세트 또는 문자셋이라고 부른다. 인코딩 타입마다 테이블이 다르며, 테이블은 구글에 검색하면 많이 올라와 있다. 테이블은 아래 그림과 같다.
문자 인코딩은 문자 정보를 표현하기 위한 글자들의 집합을 정의한 것으로, 인코딩은 인코딩 타입에 따라서 테이블의 번호도 다르다. 이런 문제를 해결하기 위하여 표준 문자셋을 개발하는 것에 대한 필요성이 많아졌다. 그 이후에 만들어진 것이 유니코드 이다.
영어는 아스키 코드(ASCII)를 통해서 모든 문자를 인코딩할 수 있지만, 초성, 중성, 종성을 결합해서 글자를 만드는 교착어인 한국어를 인코딩하기 위해서는 아스키 코드만을 사용해서는 모든 글자를 표현하지 못하는 문제가 있다. 이를 해결하기 위해서 한국어 인코딩에 대한 여러가지 방법을 논했고, 한국어를 인코딩하는 방법에는 다양한 방법이 있다.
그 예는, KS완성형(EUC-KR, cp949), 유니코드가 대표적이다.
KS완성형
우선 KS완성형에 대해서 알아보도록 한다.
KS완성형은 EUC-KR과 CP949로 나눌 수 있다. 각 방법의 정의와 개념 그리고 차이점을 작성한다.
EUC-KR
EUC-KR은 KS X 1001과 KS X 1003 을 사용하는 8비트 문자 인코딩으로 대표적인 한글 완성형 인코딩이기 때문에 완성형이라고 부른다. 또한, 2바이트로 한글을 표현할 수 있는 방법이다. 아스키 코드값은 1바이트로 표현된다. 이 방법의 특징은 한글의 11,172자( = 초성 19 * 중성 21 * 종성 27+1(없는 경우) )를 모두 표현할 수 없어서 그 당시 2,350자를 선택하여 코드표에 넣었다는 점이 특징이다. 그래서 2,350자를 선택받은 한글이라고도 불린다. 이 목록이 1987년에 만들어졌기 때문에, 맞춤법 개정 이후로 표준어에서 탈락된 단어를 표기하기 위한 글자도 몇 개 포함하고 있다.
CP949
CP949는 앞서 설명한 EUC-KR을 확장한 것이라고 보면 되는데, 그 이유는 탄생 배경에 있다. 오래 전 부터 쓰이던 방식이 EUC-KR인데, 이 인코딩에서 표현할 수 없는 한글이 있어 MS(마이크로소프트)에서 Code Page 949를 사용하게 된다. CP949는 EUC-KR보다 더 많은 한글을 표현할 수 있으며, 윈도우에서 주로 쓰이는 인코딩이다. 실제로 윈도우 메모장에서 저장되는 디폴트 값도 CP949(ANSI 로 표기 됌)이다.
EUC-KR과 CP949 방법 모두 2바이트로 한글을 표현한다는 공통점이 있다. 또한 코드 정의 영역이 <A1~FE, A1~FE>로 정의된다는 점도 역시 공통점이다.
Unicode
마지막으로 유니코드에 대해서 알아보려고 한다.
유니코드란, 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 표준 셋이다. 리눅스 시스템에서 기본값으로 사용하는 방법이다. 그중 한국어를 인코딩하기 위한 방법으로 UTF-8, UTF-16을 사용한다. (한글 코드 영역은 U+AC00~U+D7A3)
UTF-8은 문자 하나를 표현하기 위해 필요한 bit의 크기가 8bit인 것이고, UTF-16은 16bit가 필요한 것을 의미한다. 두 방법 모두 한국어 11,172자를 표현할 수 있다. UTF-8은 가변 인코딩 방식을 사용하여, ASCII 를 인코딩 할 때는 1바이트로 표현하고, 한국어 ‘가’는 3바이트로 표현한다. 그에 반해 UTF-16은 한국어 ‘가’를 2바이트로 표현한다. 한국어의 경우에는 글자당 1바이트씩 줄일 수 있는 UTF-16이 메모리를 덜 차지하는 셈이다.
주의 사항
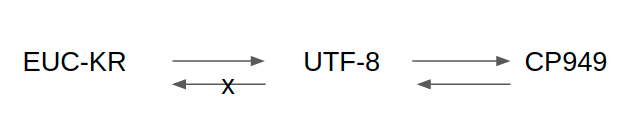
한글 인코딩이 다양하다 보니, 인코딩과 디코딩을 오갈 때 주의해야할 점이 있다. 그것은 바로, 표현가능한 관계가 양방향이 아닌 경우가 있다는 점이다. 아래 그림을 보면 쉽게 이해할 수 있다. 아래 그림에서 보다시피, UTF-8과 CP949간의 인코딩과 디코딩은 양방향으로 문제없이 이루어 진다. 하지만, UTF-8과 CP949간의 인코딩과 디코딩은 양방향으로 이루어질 수 없다. 왜냐하면 앞서 설명한 것과 같이, EUC-KR은 2350자만을 표현할 수 있는데, UTF-8은 11,172자를 모두 표현할 수 있다보니, 글자가 깨지게 되는 것이다.
reference